


This is the second part of our Kafka Series.
- Into to Kafka - Topics
- Producers
- Consumers
- Inside Kafka CLI
- Demo
This time we'll discuss Producers.
What is a Producer
Producers map messages to a topic partition. The producer sends the produce request to the leader of the partition, the replicas are kept in-sync by fetching from the leader. If the leader shuts down or fails, the next leader is chosen from the in-sync replicas.
Messages written to the partition leader are not immediately readable by consumers (more on this later).
Message Keys
One can choose to sent a key with the message (string, integer, etc). All messages with the same non empty key will be sent to the same partition (possibility of achieving ordering within the same topic partition). If the key is not provided, the message will be sent using Round Robin, which will distribute writes equally across partitions.
Response Acknowledgments
Producers can choose to receive acks of data writes.
ack=0 : Producers won't wait for the ack - This is useful when its acceptable to have potential data loss. (This setting will also maximize throughput) Ex: Metrics or log collection.

ack=1 : Producers will wait for leader acknowledgment - Leader response is requested, but replication is not guaranteed (happens in the background). If the ack is not received, the producer may retry.
If the leader broker goes offline but replicas haven't replicated data yet, we have data loss.

ack=all : Producers will wait for the leader and replicas acknowledgment. (Which will add latency but also safety. When all in-sync replicas have acknowledged the write, then the message is considered committed, which makes it available for reading.
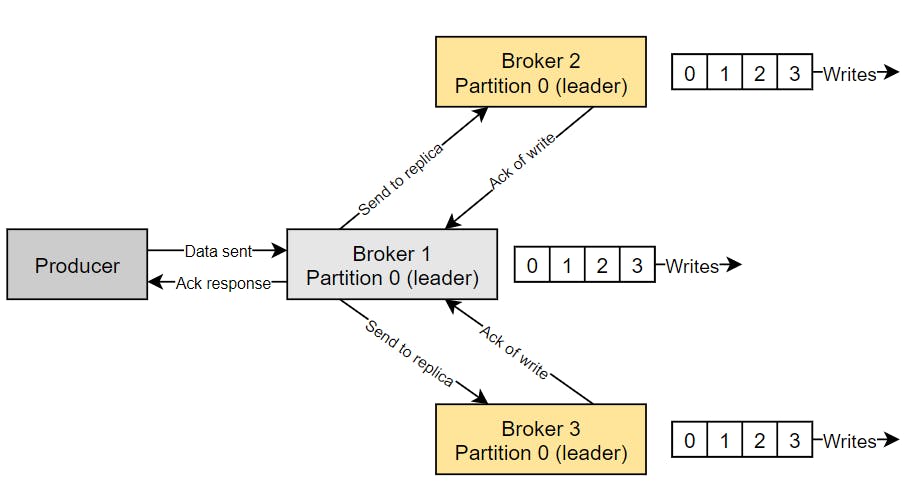
ack=all must be used in conjunction with min.insync.replicas configuration setting, and it can be set at the broker or topic level. As an example: min.insync.replicas=2 means at least 2 brokers that are in the ISR (including the leader) must respond that they have received the data.
If we use replication.factor=3, min.insync=2 and ack=all, means the system can handle 1 broker down, otherwise the producer will receive an exception on send (NOT_ENOUGH_REPLICAS).
Producer Retries:
Setting retry to a value greater than zero will cause the client to resend any message whose send fails with a potentially transient error.
There are other configurations that can be set for producer retries:
retry.backoff.ms: The amount of time to wait before attempting to retry a failed request to a given topic partition. This avoids repeatedly sending requests under some failure scenarios.
delivery.timeout.ms: The producer won't retry forever, its bounded to a timeout. There is a upper bound on the time to report success or failure after a call to send() returns. This limits the total time that a record will be delayed prior to sending, the time to await acknowledgement from the broker (if expected), and the time allowed for retriable send failures.
In case of retries, there is a chance that messages will be sent out of order. Key-based ordering can be an issue. To address this scenario there are two solutions:
- Set the setting which controls how many producers requests can be made in parallel:
max.flight.requests.per.connectionto 1 (default is 5) - This can dramatically impact throughput. - Idempotent producers
Idempotent Producers
A producer can introduce duplicate messages in Kafka due to network errors.
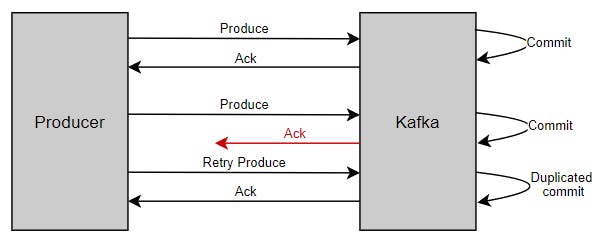
Versions above 0.11 introduced idempotent producers which won't introduce duplicates.
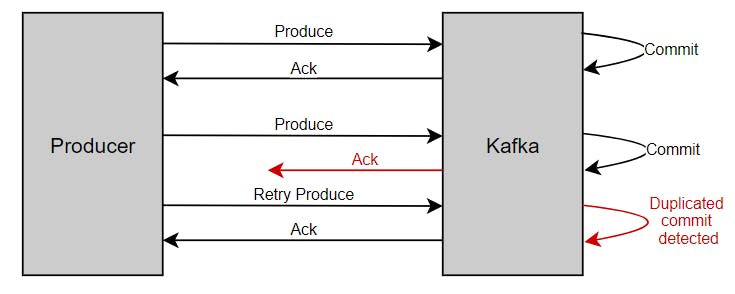
Idempotent delivery enables the producer to write a message to Kafka exactly once to a particular partition of a topic during the lifetime of a single producer without data loss and order per partition. The setting enable.idempotence needs to be set to true.
The way Kafka achieves this is by using the concept of PID (Product id) and sequence numbers. The producer keeps incrementing the sequence number on each message published which maps with a unique PID. The broker always compares the current sequence number with the previous one and it rejects if the new one is not +1 greater than the previous one which avoids duplication. If the producer restarts, new PID gets assigned, so idempotency is only promised for a single producer session.
Running a "safe producer" might impact throughput and latency.
Message Compression
Producers usually send text-based data. Compression can be enabled at producer level and doesn't require any extra configuration. By default no compression is used.
When to use compression:
- When the application can tolerate slight delay in message dispatch, enabling compression increases message dispatch latency. Although given the smaller request size, it should make it faster to transfer the message over the network, which would also increase throughput.
- When data is fairly repetitive like server logs, XML and JSON messages.
- CPU processing is not critical, as producers must commit CPU cycles to compression.
When compression might not help:
- When the volume of data is not high. Infrequent data might not fill up message batches and that can affect compression ratio.
- Data is textual. This data might contain unique sequences of characters that might not compress very well.
- Application is time critical and one cannot tolerate delay in message dispatch.
There are 4 compression types:
- Gzip
- Lz4
- Snappy
- Zstd
Producer Batching
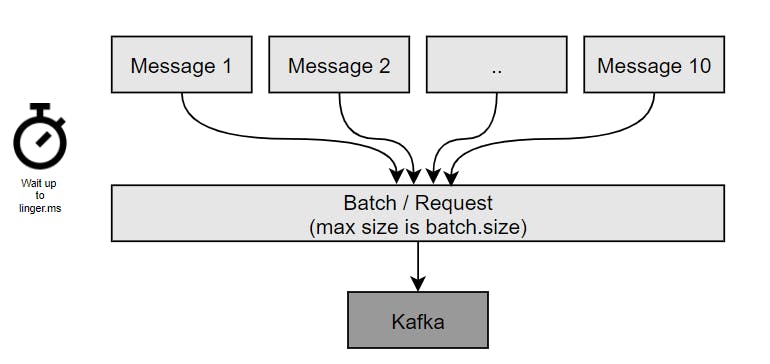
By default, Kafka tries to send messages as soon as possible. Kafka will have up to 5 messages in flight. If there's more while others are in flight, Kafka will start batching them while they wait to be sent all at once.
If producers can tolerate a slight delay before messages are sent out, this could increase the chance of messages being sent together in a batch. In order to introduce this lag, one would need to configure linger.ms setting. At the expense of introducing a small delay, we could end up increasing throughput, compression and efficiency in the producer. If the batch is full (batch.size - max number of bytes 16KB) before the end of the linger.ms, messages will be dispatched right away. Messages bigger than batch.size won't be batched.
Sometimes, increasing batch size could also help increase compression, throughput and efficiency of the request.
If the producer can't send messages it will start to use its memory buffer (32MB) and send will eventually start to block. max.block.ms setting represents the time send() will block until it throws an exception.
But that's enough of Producers for now, next up we will go through consumers.
If you enjoyed this post, please give it a like or a share!